Web scraping and security
Introduction
 Web scraping is an automated process of extracting structured or unstructured data from the internet. This is a very effective method for gathering large amounts of information quickly and efficiently. In the digital age, data is becoming increasingly important in all aspects of life. From marketing to analysis, they are the sinews of war for many companies. Web scraping is one of the best ways to get this data from the internet. Web scraping consists of automatically extracting the content of websites, to obtain structured and easily usable data. Concretely: software retrieves the required information from the source code of the relevant web pages, then returns it to an organized spreadsheet-type database. The user of the web scraper thus has an overview of all the information he needs. Web scraping is a technique that can be used by individuals to compare the selling prices of the same product on different e-commerce sites, for example. Professionals can also use web scraping, for competitive intelligence purposes, for example. The technique, in any case, must be implemented in compliance with the GDPR and intellectual property rights.
Web scraping is an automated process of extracting structured or unstructured data from the internet. This is a very effective method for gathering large amounts of information quickly and efficiently. In the digital age, data is becoming increasingly important in all aspects of life. From marketing to analysis, they are the sinews of war for many companies. Web scraping is one of the best ways to get this data from the internet. Web scraping consists of automatically extracting the content of websites, to obtain structured and easily usable data. Concretely: software retrieves the required information from the source code of the relevant web pages, then returns it to an organized spreadsheet-type database. The user of the web scraper thus has an overview of all the information he needs. Web scraping is a technique that can be used by individuals to compare the selling prices of the same product on different e-commerce sites, for example. Professionals can also use web scraping, for competitive intelligence purposes, for example. The technique, in any case, must be implemented in compliance with the GDPR and intellectual property rights.
The basic principles
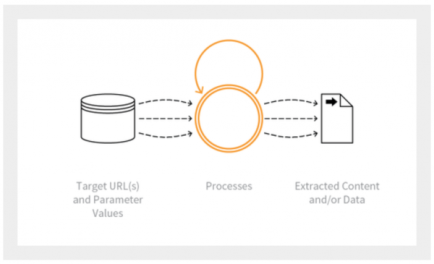
 Web scraping is a technique that automatically extracts data and information from the web. This method makes it possible to quickly collect data from different websites. Due to this convenience, web scraping is embraced by many organizations. The interest of web scraping is to automate the extraction of data. Different technologies allow you to do web scraping: some software publishers offer turnkey solutions; another way is to code a web scraping program yourself.
Without programming knowledge, a person can use a platform in SaaS mode or a browser extension to extract the content of his choice from the websites he selects.
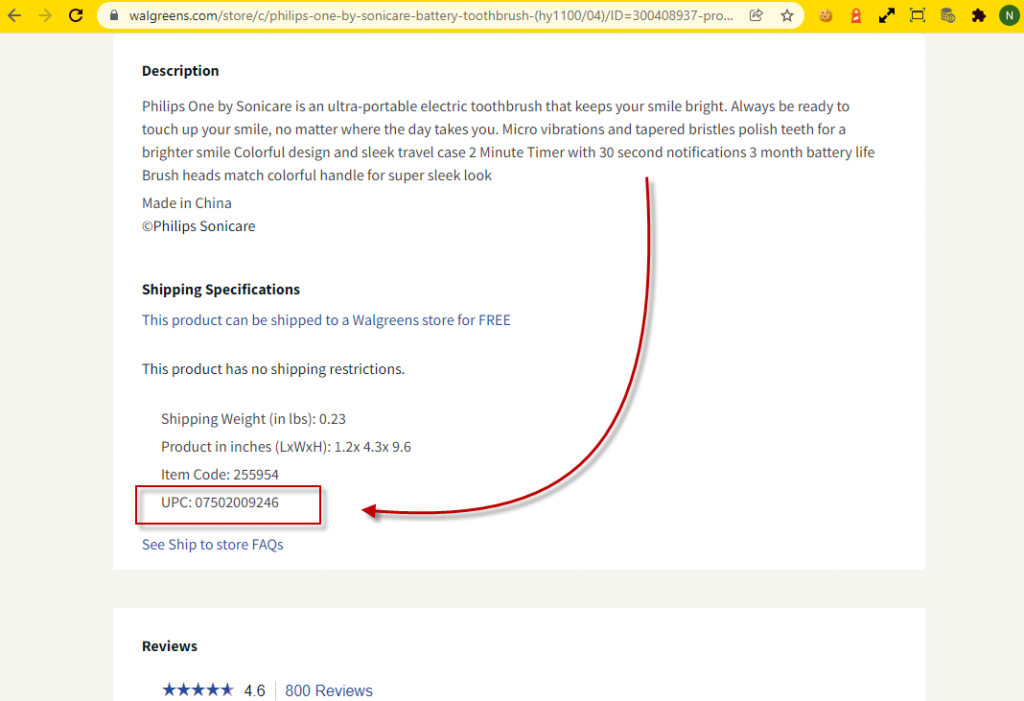
It is possible to code the extraction by writing a script in a programming language such as Python. You must list the relevant web pages, isolate the interesting information in the source code, and code a systematic extraction instruction.
Web scraping is a technique that automatically extracts data and information from the web. This method makes it possible to quickly collect data from different websites. Due to this convenience, web scraping is embraced by many organizations. The interest of web scraping is to automate the extraction of data. Different technologies allow you to do web scraping: some software publishers offer turnkey solutions; another way is to code a web scraping program yourself.
Without programming knowledge, a person can use a platform in SaaS mode or a browser extension to extract the content of his choice from the websites he selects.
It is possible to code the extraction by writing a script in a programming language such as Python. You must list the relevant web pages, isolate the interesting information in the source code, and code a systematic extraction instruction.