How to create web scraper? New WebScraper development User Manual
Creation of the web scraper : user interface.
In the top menu of service click on "Create" button: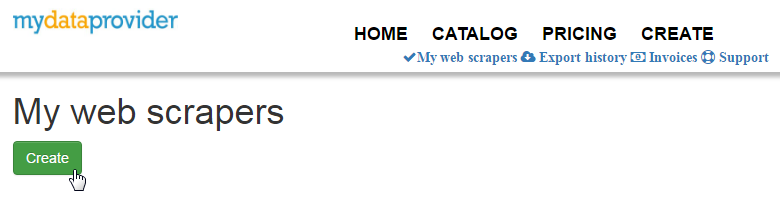 In opened dialog choose Empty web scraper
In opened dialog choose Empty web scraper
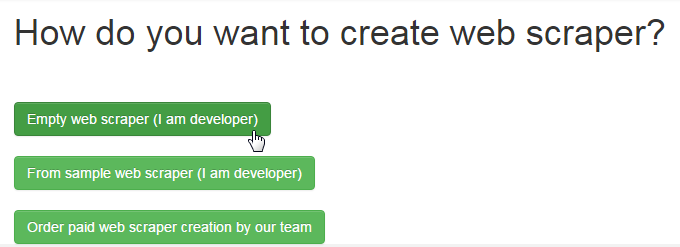
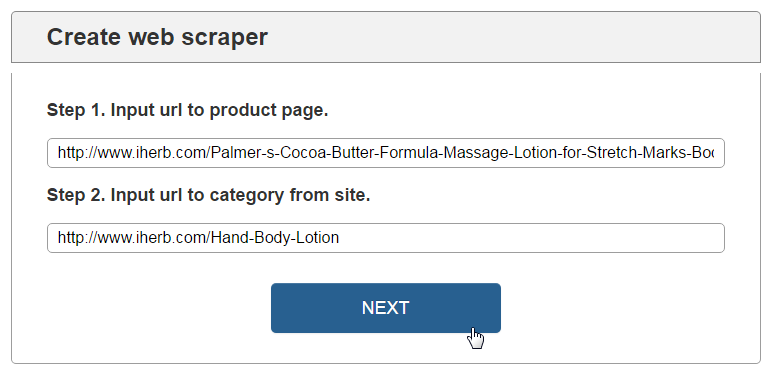 We copy category URL and product URL from donor site after Next we create the scraper and we pass into settings:
We copy category URL and product URL from donor site after Next we create the scraper and we pass into settings:
 Now we can choose it in the list of My web scrapers menu anytime:
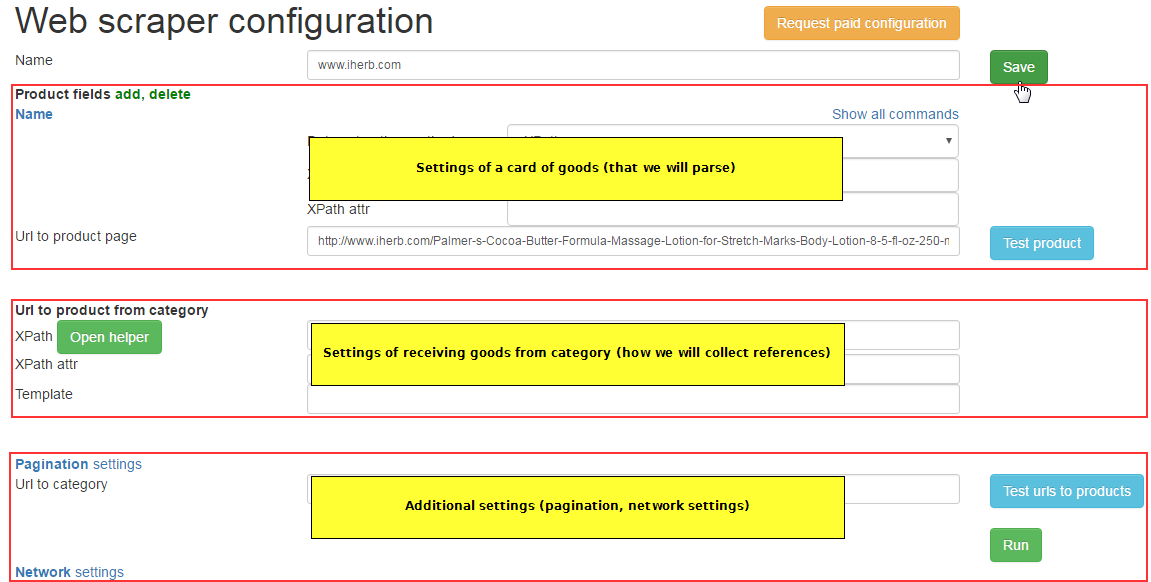
The editor of settings it is conditionally possible to divide into several parts:
settings for unloading of information from a products page
control of collecting references in category for products pages
a pagination (it is a lot of pages with products in one category)
network settings (delays, coding, repeated attempts, etc.)
Importance (priorities) of settings:
item 1-2 always;
item 3 - not always, but it is frequent;
item 4 - sometimes, only the coding, the others it is very rare.
In the same sequence of control are also located in the editor:
Now we can choose it in the list of My web scrapers menu anytime:
The editor of settings it is conditionally possible to divide into several parts:
settings for unloading of information from a products page
control of collecting references in category for products pages
a pagination (it is a lot of pages with products in one category)
network settings (delays, coding, repeated attempts, etc.)
Importance (priorities) of settings:
item 1-2 always;
item 3 - not always, but it is frequent;
item 4 - sometimes, only the coding, the others it is very rare.
In the same sequence of control are also located in the editor:
Fields from product page
Standard fields
The following fields are created by default: SKU - the article of products. If not to adjust him, will be generated automatically. Name - a products name, has to be always. Price - the products price. Quantity - quantity of products if is on the donor website. Full description - the description of products Short description - the simplified description of products Manufacturer - pictures of products. Images - pictures of products. META_TITLE title for SEO. META_KEYWORDS keywords (tags) for SEO. META_DESCR description for SEO. Category - category of products. Standard fields it is enough to make the web scraper in most cases.Additional fields
Except standard fields it is possible to add new or to delete existing: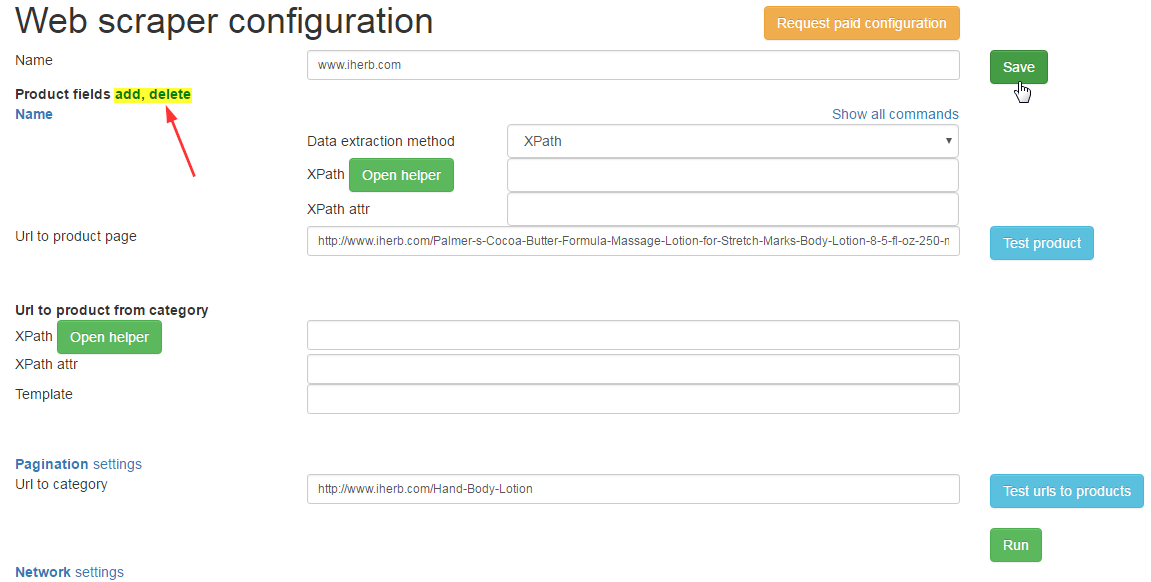
Settings of fields of a product page
The first that needs to be made, it to specify the reference to a product page in a floor "Reference to products" products on which we will test everything and to adjust.C. Extraction methods
There are two options of extraction of data XPath and RegEx. It is recommended to be used also costs by default XPath, RegEx - extreme cases or if you know it better xPath.D. XPath
XPath (XML Path Language) is a query language for selecting nodes with data from an XML document.E. RegEx
RegEx (Regular expressions) formal language of search and implementation of manipulations with sublines in the text, based on use metacharacters. In settings it is used very rarely, in extreme cases.F. «xpath» and «xpath attr» commands
xpath - we write xpath for extraction of content necessary to us from the donor in this field. In example we parse <h1> tag with product name. xpath attr - the name of attribute which value is necessary for us from the tag which we take in xpath.
For pictures it can be the img tag and src attribute in which the link to a photo.
xpath attr - the name of attribute which value is necessary for us from the tag which we take in xpath.
For pictures it can be the img tag and src attribute in which the link to a photo.
G. Additional commands (Show all commands)
Additional fields are necessary in cases if to receive necessary result not xpath allows: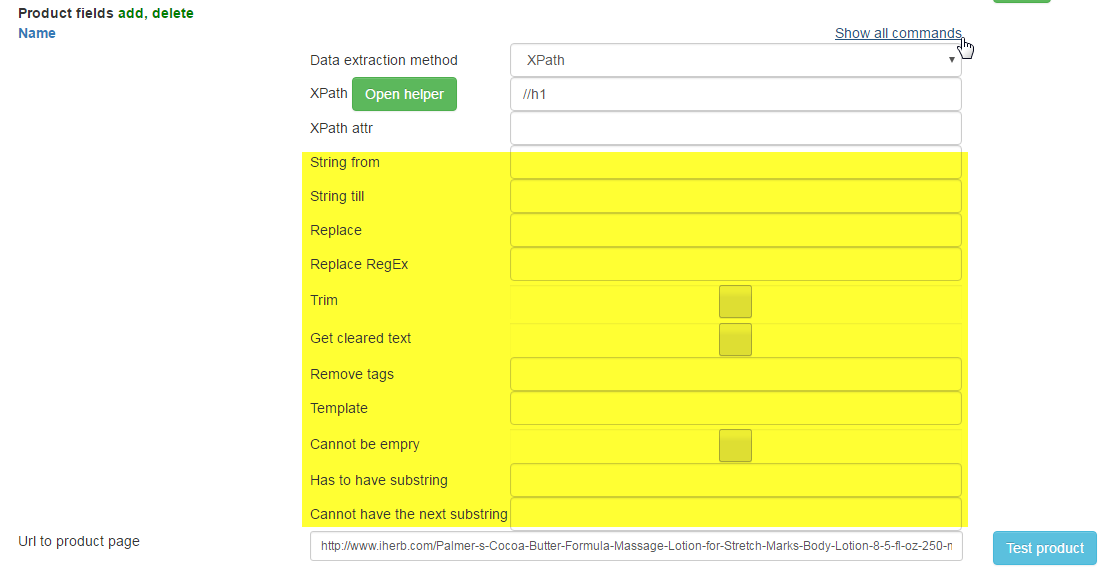 Additional fields process the result received from xpath.
Description of additional fields:
String from - the word since which to take data.
String till - the word to which to take data.
Replace - we replace symbols/word. Example 1: the usd [--->] euro - the word of usd will be replaced on euro. Example 2: usd - the word of usd will be removed (it is often applied in case of extraction
prices). Example 3: the usd [--->] the price [--->] the cost of - usd will replace euro with euro, the price of cost, gaps will removed. From the last example we see that transfer several options goes through
Replace RegEx - RegEx replacement
Trim - we delete gaps/tabulation (trim) on the right and at the left.
Get cleared text - to clear the text of all a html-marking.
Remove tags - removal not of the necessary tags together with their contents, for example references or photo from the description: aimg. All references and a photo will be removed from the description.
Template - can be added to the obtained data other information on a template. Example: the reference to a card of products or a photo not full, it is necessary to add the domain:
http://site.domain.com/{0} where {0} are data which are taken by adjusted field.
Cannot be empty - the filter. If it is included, products which will have this field
empty, won't remain. For example - for a products name, i.e. products without name not
will remain.
Has to have substring - the filter. For example, the status of products on the website. If we enter in this field "Available" is also taken by the field "Available" - everything is OK. If taken not coincides about value of a subline - the products don't remain.
Cannot have the next substring - as well as an "Has to have substring" but negative.
Additional fields process the result received from xpath.
Description of additional fields:
String from - the word since which to take data.
String till - the word to which to take data.
Replace - we replace symbols/word. Example 1: the usd [--->] euro - the word of usd will be replaced on euro. Example 2: usd - the word of usd will be removed (it is often applied in case of extraction
prices). Example 3: the usd [--->] the price [--->] the cost of - usd will replace euro with euro, the price of cost, gaps will removed. From the last example we see that transfer several options goes through
Replace RegEx - RegEx replacement
Trim - we delete gaps/tabulation (trim) on the right and at the left.
Get cleared text - to clear the text of all a html-marking.
Remove tags - removal not of the necessary tags together with their contents, for example references or photo from the description: aimg. All references and a photo will be removed from the description.
Template - can be added to the obtained data other information on a template. Example: the reference to a card of products or a photo not full, it is necessary to add the domain:
http://site.domain.com/{0} where {0} are data which are taken by adjusted field.
Cannot be empty - the filter. If it is included, products which will have this field
empty, won't remain. For example - for a products name, i.e. products without name not
will remain.
Has to have substring - the filter. For example, the status of products on the website. If we enter in this field "Available" is also taken by the field "Available" - everything is OK. If taken not coincides about value of a subline - the products don't remain.
Cannot have the next substring - as well as an "Has to have substring" but negative.
H. Links to products pages from category
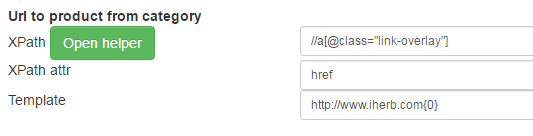 The fields XPath, XPath attr and Template which are necessary for control of extraction of references on card of products are similar to fields of a card of products and were described above.
The fields XPath, XPath attr and Template which are necessary for control of extraction of references on card of products are similar to fields of a card of products and were described above.
Pagination (settings)
Pagination is a navigation according to pages of category with products. In category usually not all products, but limited quantity (10,20, etc.), other products are removed - on following pages: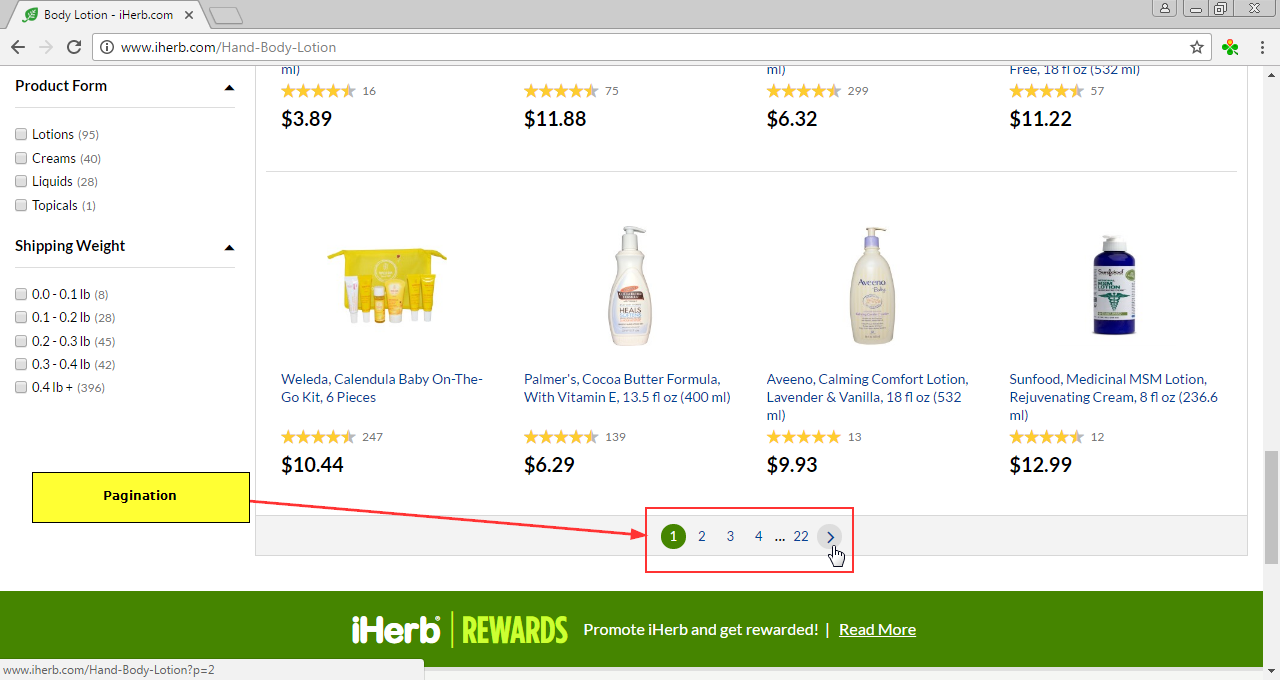 To take away products from all pages, it is necessary to adjust Pagination.
Method pagination processing - the Urls template and via the next product page.
Pagination through Urls template - the second and the subsequent pages are on to the clear sample address where it is added, for example ?page=2, ?page=3, etc.
I.e. only the figure with a certain step changes.
Template for pagination - the parameter which is added to the reference, for example ?page={0}.
Step for index changing - a step with which the number in a template upon transition between adjacent changes
pages.
Start index value - number with which the second page begins.
Pagination through the next product page - control as for usual
fields of a card of products through Xpath, Xpath attr and the Template.
To take away products from all pages, it is necessary to adjust Pagination.
Method pagination processing - the Urls template and via the next product page.
Pagination through Urls template - the second and the subsequent pages are on to the clear sample address where it is added, for example ?page=2, ?page=3, etc.
I.e. only the figure with a certain step changes.
Template for pagination - the parameter which is added to the reference, for example ?page={0}.
Step for index changing - a step with which the number in a template upon transition between adjacent changes
pages.
Start index value - number with which the second page begins.
Pagination through the next product page - control as for usual
fields of a card of products through Xpath, Xpath attr and the Template.
Network settings
Delay between requests - if for some reason because of the frequent address to to the website voznimat problems with parsing, it is possible to use a delay between inquiries. 1000 ms = are specified 1 sec. in ms (milliseconds). Timeout for request - waiting time of the answer from the server (donor). Retry requests number - the number of attempts which page will be to be downloaded in case of unsuccessful loading. The specified number of times will be downloaded or still successfully won't download. DeflateGzip enable - to request compulsory compression from the donor. Web site charset - is defined automatically, but if there are problems - it is possible to specify by hands. Max products number in category - the maximum quantity of products which it is necessary to unload from category. String for blocking detection - during blocking (Bang) isn't always removed 404 mistake. To distinguish such cases - we enter a line which is removed during Bang.EXAMPLE OF SETUP OF THE WEB SCRAPER
It is possible to adjust fields of products one after another, it is possible in any other the sequences as it is convenient. If any fields aren't necessary to you, for example, the article, quantity - them it is possible not to adjust and just to pass. Product for an example on which we will do custom web scraper: http://www.iherb.com/Palmer-s-Cocoa-Butter-Formula-Massage-Lotion-for-Stretch-Marks-Body-Lotion-8-5-fl-oz-250-ml/26938 For inspect donor site we will use Inspect tool from Chrome DevTools.I. SKU of products
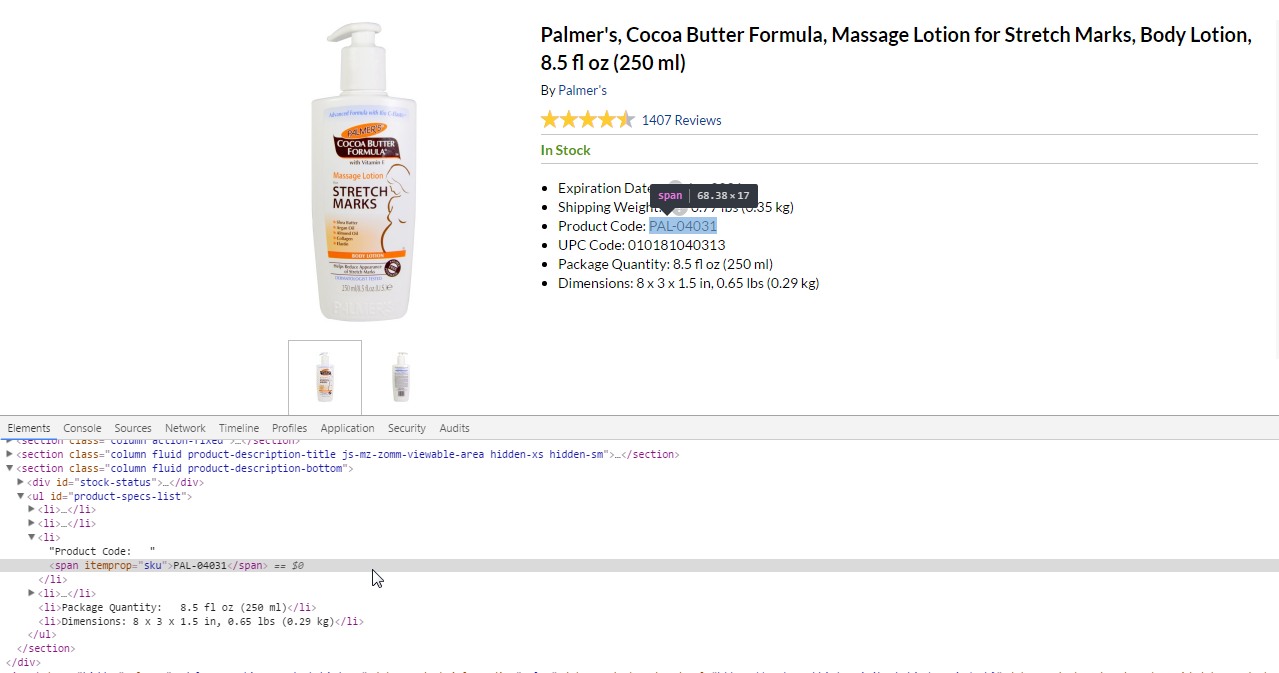 Is in span with the itemprop="sku". Xpath turns out such look:
//span[@itemprop="sku"]
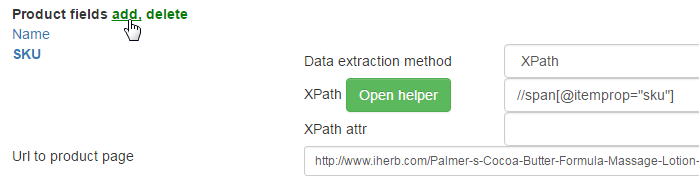
also we add new product field to settings:
Is in span with the itemprop="sku". Xpath turns out such look:
//span[@itemprop="sku"]
also we add new product field to settings:
 Press the Save and Test product button and check results:
Press the Save and Test product button and check results:
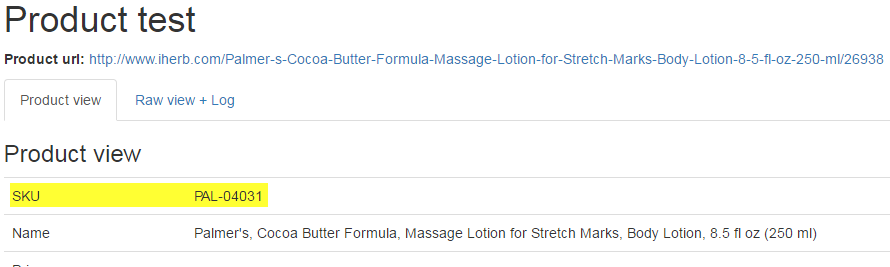 Now what is necessary. The article was adjusted.
Now what is necessary. The article was adjusted.
J. Products name
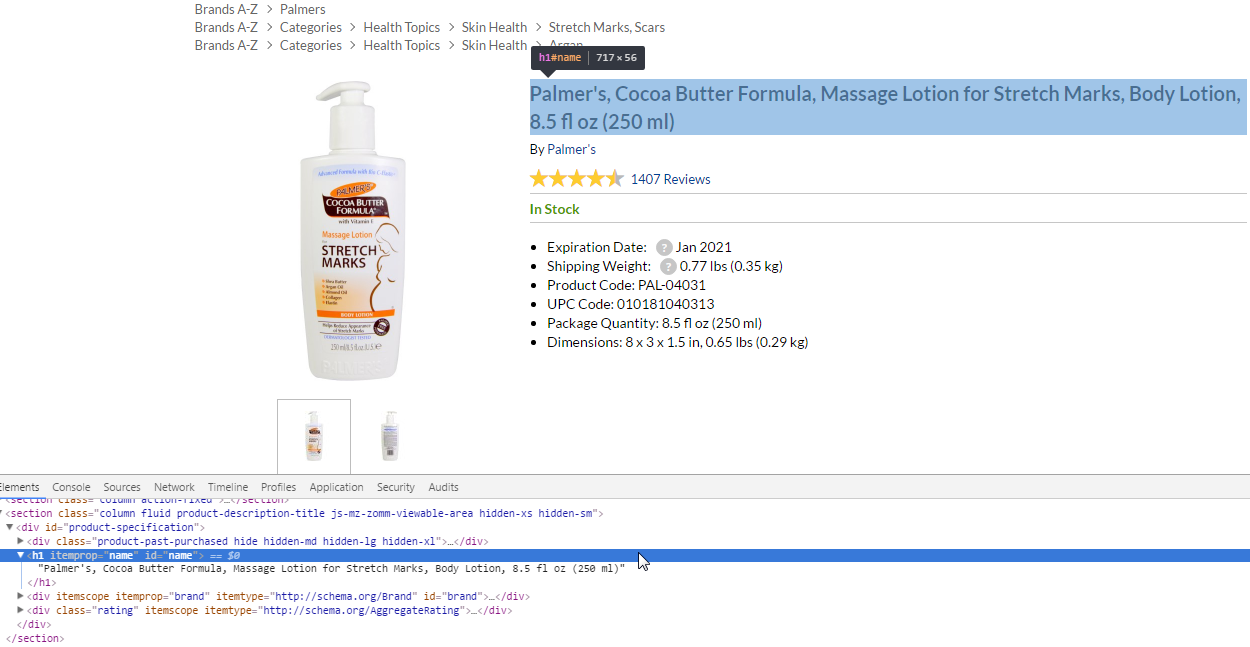 Is in <h1> tag with attribute itemprop="name". xpath turns out:
//h1[@itemprop="name"]
Is in <h1> tag with attribute itemprop="name". xpath turns out:
//h1[@itemprop="name"]
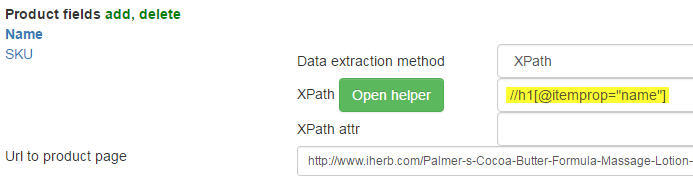 Test:
Test:
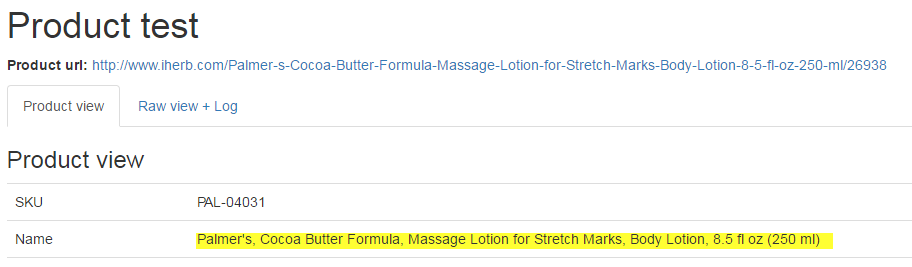 The name of products is also ready.
The name of products is also ready.
K. Price
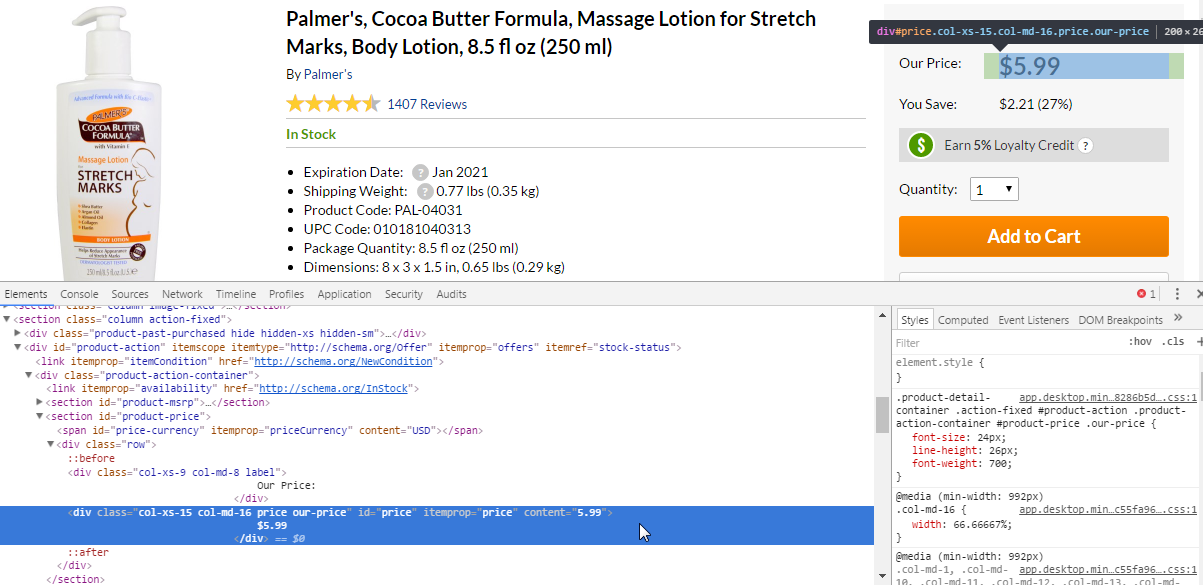 There is a price in div of the class with "price", "our-price" and some other. Xpath turns out:
//div[contains(@class,"price")]
But in test results we can see wrong price because page have many prices (MSRP and other products in footer). We must specify one unique combination. In this case class "our-price" is more preffered and Xpath turns out:
//div[contains(@class,"our-price")]
There is a price in div of the class with "price", "our-price" and some other. Xpath turns out:
//div[contains(@class,"price")]
But in test results we can see wrong price because page have many prices (MSRP and other products in footer). We must specify one unique combination. In this case class "our-price" is more preffered and Xpath turns out:
//div[contains(@class,"our-price")]
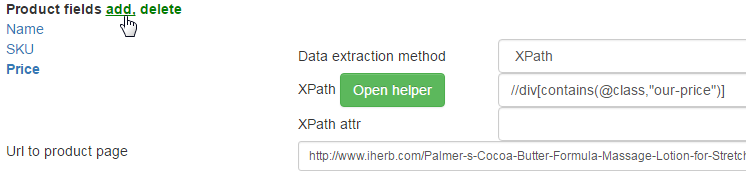
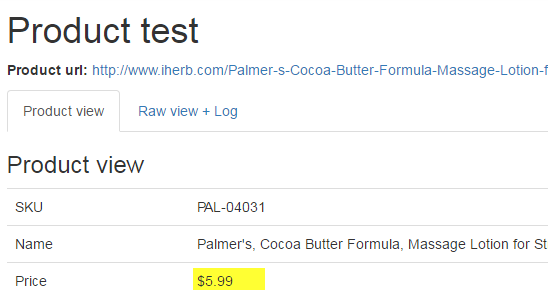 Test:
Except the price there are "$" which aren't necessary to us. It is possible to move away them through replacement. Click Show all commands in top of product fields and fill Replace string:
Test:
Except the price there are "$" which aren't necessary to us. It is possible to move away them through replacement. Click Show all commands in top of product fields and fill Replace string:
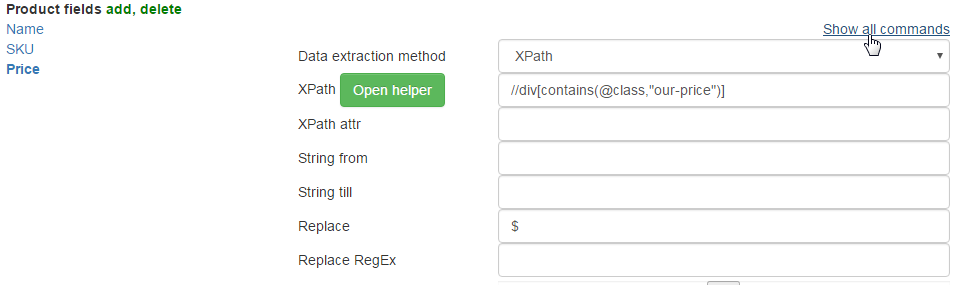 Test:
Test:
 The price is ready.
Setup of the description of products is similar to the previous fields:
The price is ready.
Setup of the description of products is similar to the previous fields:
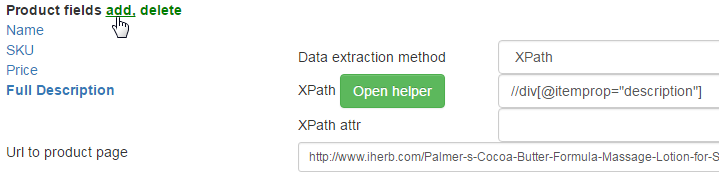
L. Products images
If at products it is more than 1 photo, control is able to take away all photos at once. For this purpose it is necessary to make control for the first photo. To take all photos use container with all photos of product. The first photo is in the <a> tag which in turn in tag div with attribute class="mz-image-selector-container" and all it inside tag div with id="product-image". Control will be following:
xpath: //div[@id="product-image"]//div[@class="mz-image-selector-container"]//a
xpath attr: href (we need the attribute with link to a photo)
The first photo is in the <a> tag which in turn in tag div with attribute class="mz-image-selector-container" and all it inside tag div with id="product-image". Control will be following:
xpath: //div[@id="product-image"]//div[@class="mz-image-selector-container"]//a
xpath attr: href (we need the attribute with link to a photo)
 Test:
Test:
 All photos are downloaded normally.
All photos are downloaded normally.
M. Features
Still these products have features which can also be downloaded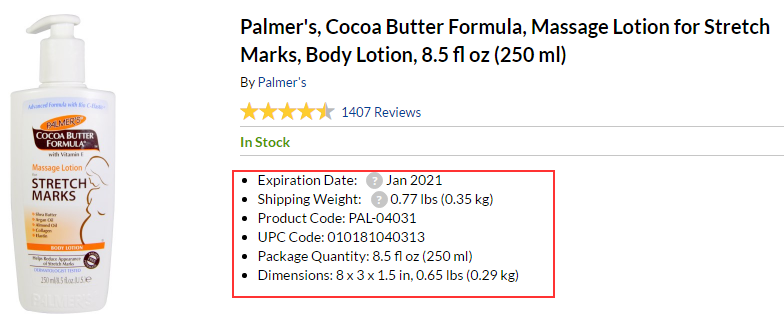 For this purpose it is necessary to add the additional field "Set of features":
For this purpose it is necessary to add the additional field "Set of features":
 There will be two new fields:
DYNAMICLIST_NAMES - the name of the characteristic
DYNAMICLIST_VALUES - value of the characteristic
How to adjust: the logician similar as well as with a photo - needs to be shown in settings how to receive the first feature and others the web scraper will collect itself (since a way to them same).
We pass to settings.
There will be two new fields:
DYNAMICLIST_NAMES - the name of the characteristic
DYNAMICLIST_VALUES - value of the characteristic
How to adjust: the logician similar as well as with a photo - needs to be shown in settings how to receive the first feature and others the web scraper will collect itself (since a way to them same).
We pass to settings.
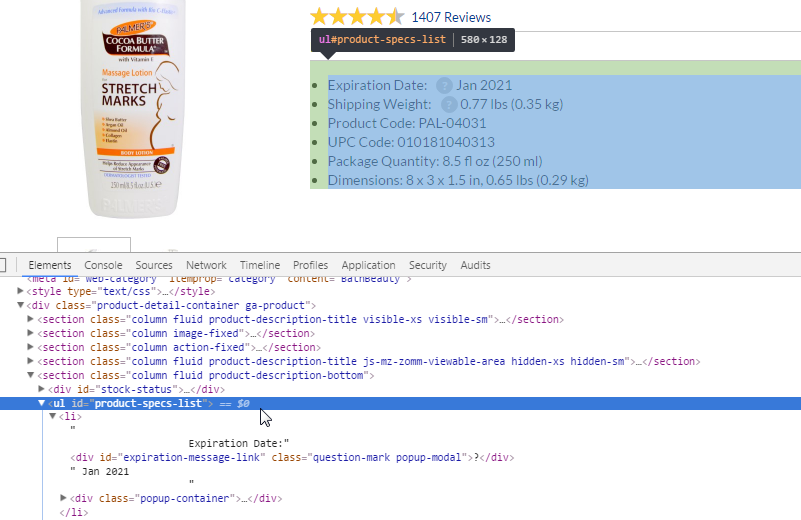 Feature name:
Features is in the tag with id product-specs-list and listed through <li> tag:
//*[@id="product-specs-list"]/li
To take only name part we must set String till=:
Feature name:
Features is in the tag with id product-specs-list and listed through <li> tag:
//*[@id="product-specs-list"]/li
To take only name part we must set String till=:
 Feature values is filled the same as name but positioned after : and we must set String from=:. Also we remove ? from text by replacing.
Feature values is filled the same as name but positioned after : and we must set String from=:. Also we remove ? from text by replacing.
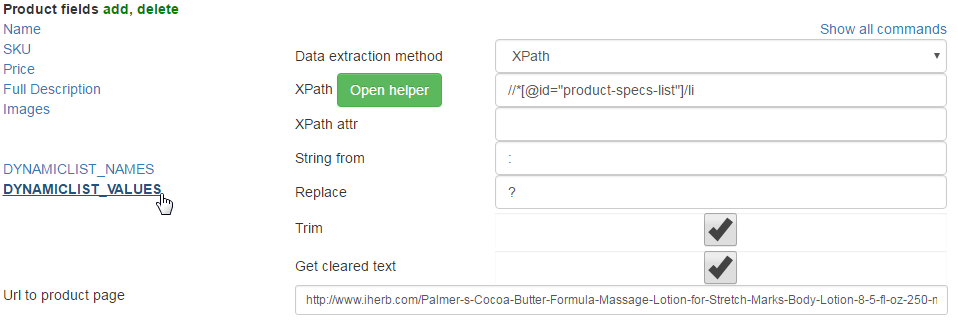 For clean HTML tags Get cleared text must be set in both options. And Trim to remove spaces.
It is necessary to test at once two parameters together, otherwise there will be a mistake (if there is no value or names of a character - it doesn't remain).
For clean HTML tags Get cleared text must be set in both options. And Trim to remove spaces.
It is necessary to test at once two parameters together, otherwise there will be a mistake (if there is no value or names of a character - it doesn't remain).

N. One feature
We will consider setting up one feature on the example of product availability: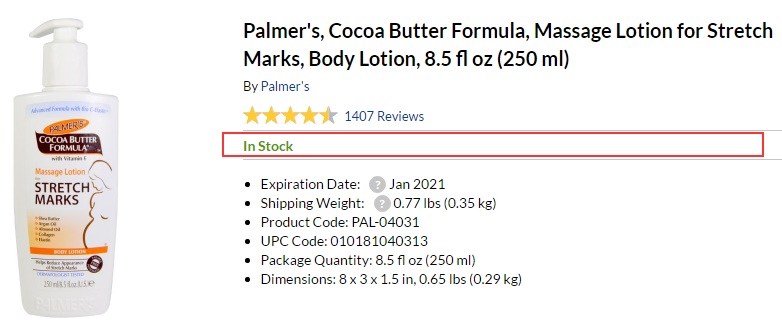 For a start it is necessary to add the additional field "One feature" where to specify name:
For a start it is necessary to add the additional field "One feature" where to specify name:
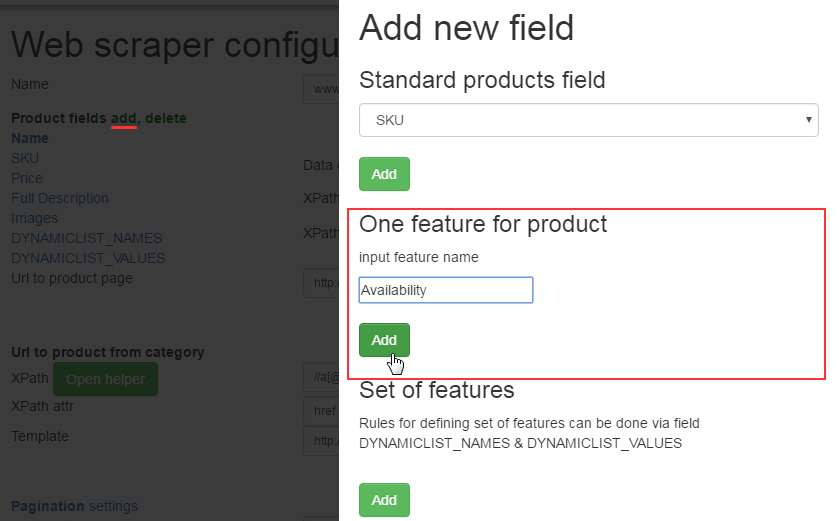 There was a new field of Dynamic_Availability which needs to be adjusted.
There was a new field of Dynamic_Availability which needs to be adjusted.
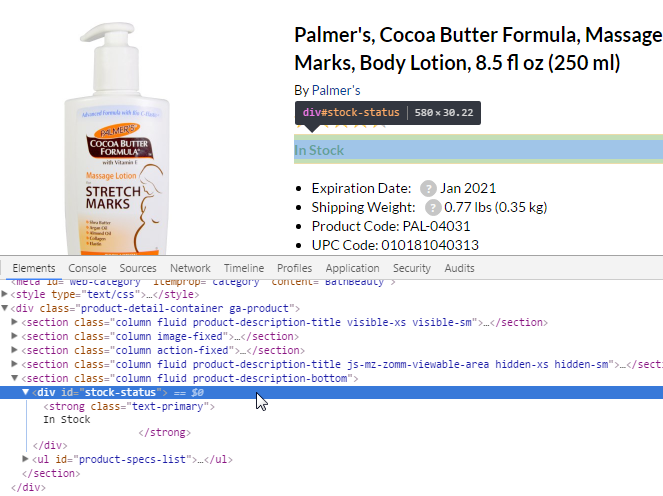 Xpath: //div[@class="item"]//p[@class="lnk"]//a
Xpath: //div[@class="item"]//p[@class="lnk"]//a
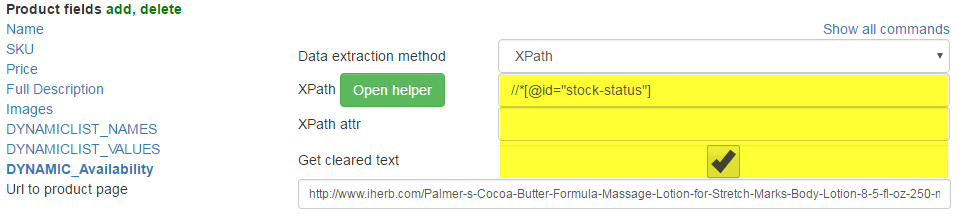 Test:
Test:

O. Links to products pages from category
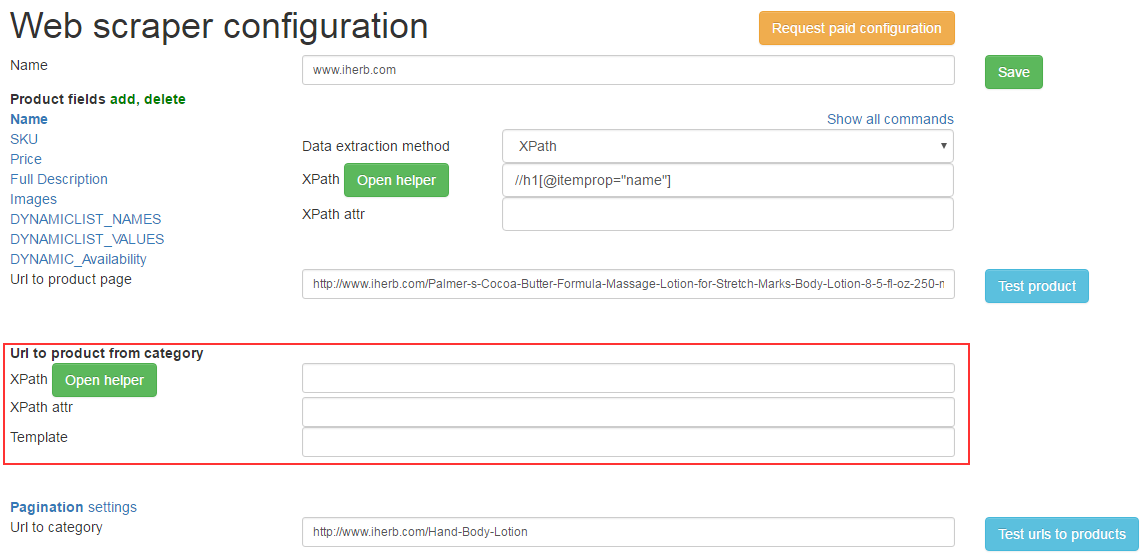 We need to adjust obtaining references to cards of products from category.
Usually all references are located the same therefore it is necessary to make settings for obtaining one reference to a products card (similarly as well as photo of products).
All three settings for us are already familiar: Xpath, Xpath attr, Template.
We watch where there are references to a products card:
We need to adjust obtaining references to cards of products from category.
Usually all references are located the same therefore it is necessary to make settings for obtaining one reference to a products card (similarly as well as photo of products).
All three settings for us are already familiar: Xpath, Xpath attr, Template.
We watch where there are references to a products card:
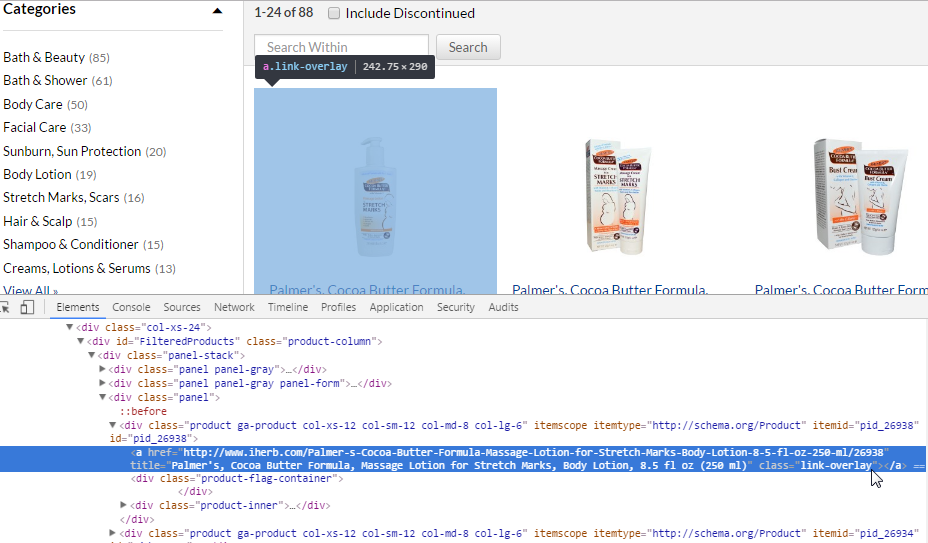 Xpath of the following look turns out:
//a[@class="link-overlay"]
Xpath attr: href - since we need the reference.
If link not full - we use the Template where we add the domain
http://www.iherb.com{0} but in this case link is full.
Control is ready, we save and press to test links to products:
Xpath of the following look turns out:
//a[@class="link-overlay"]
Xpath attr: href - since we need the reference.
If link not full - we use the Template where we add the domain
http://www.iherb.com{0} but in this case link is full.
Control is ready, we save and press to test links to products:
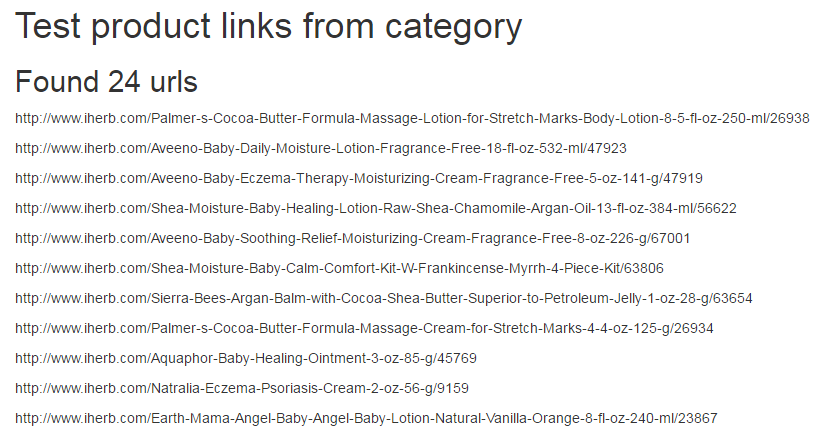 24 links are found, as it was required to receive.
Now it is possible to start the web scraper!
24 links are found, as it was required to receive.
Now it is possible to start the web scraper!