Python is very popular for web scraping programming language. In this Article will be described how to use python 3 for web scraping and will be used BeautifulSoup / bs4 library. The internet contains tons of information, it is so hard for us to get it all and absorb it even if we spent our whole life so what to do when you need to access and analysis this information.
That is when the role of python web scraping comes on. Web scraping is a powerful technique to get and gather data from web pages and preserve the data structure at the same time, also you can get your data in the most useful form.
Video demo
Lets define sample Python Scraper
Will be created small script with the next functions
1) extract products price from Amazon product page
2) script has to support Caching of request (it is very important for debugging & fast development)
Lets look at HTML code & find tags what we have to find at targeted page.
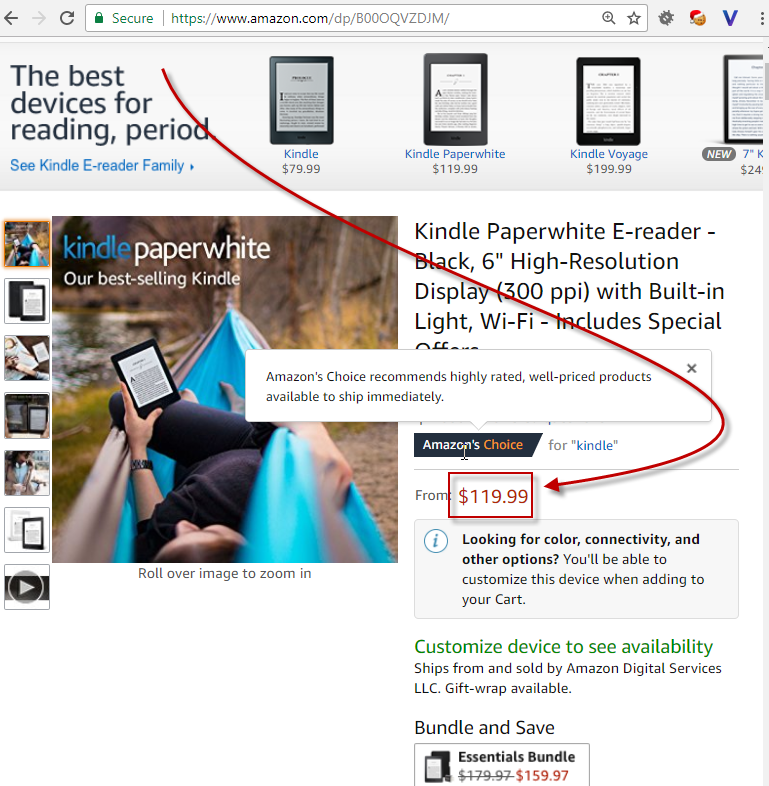
Just for sample lets open the next url https://www.amazon.com/dp/B00OQVZDJM/
it is Amazon Kindle reader.
Web scraping with Python Amazon
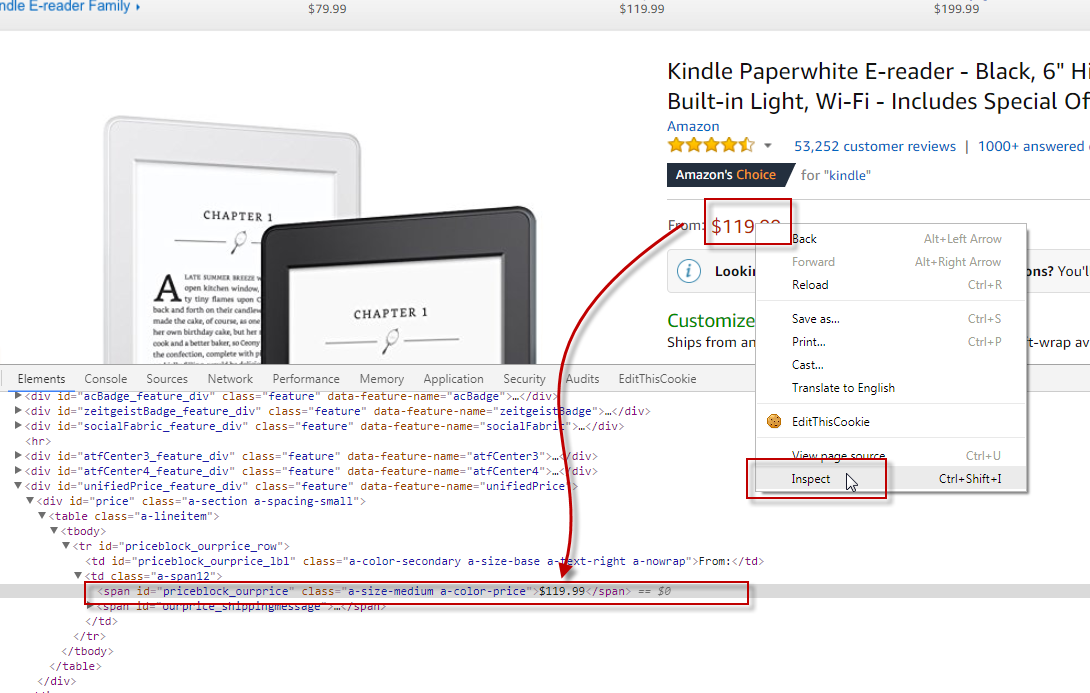
The best way to find amazon product price tag is to use google chrome Inspect Element Tool under Amazon price, find how to do it on the next image:
Code Python Web Scraper
Web Scraping python beautifulsoup
Lets Define libraries
We will use BeautifulSoup & urllib.request. urllib.request is very importand here because we will use python 3.5.
from urllib.request import urlopen
from bs4 import BeautifulSoup
Beautifulsoup vs Scrapy
Beautifulsoup vs Scrapy is a very frequently question when you start python web scraping. When you only start python web scraping & do not have experience in it we recommend to use Beautifulsoup because it is simple and does not require special knowledge to manage it. Scrapy is nice framework for web scraping, but you have to have experience in python itself for using it.
Python 3 Web Scraping
We prefer to use Python 3 for Web Scraping. Why ? Because Python 3 supports different code pages & different encoding better : it is easier to develop scraper using python 3.
Code html_load function
As we defined at our goals we wanted to support caching for our web scraping requests. How it will be done: will be created CACHE directory and each request will be saved at this directory.
So it means that if you want to repeat web requests during code debugging you will take data from CACHE folder.
def html_load(url):
print("html_load ", url)
dir_path = os.getcwd()
cache_dir = os.path.join(dir_path, 'cache')
if (not os.path.isdir(cache_dir)):
os.makedirs(cache_dir)
file_name = str(slugify(url)) + ".html"
cache_file = os.path.join(cache_dir, file_name)
html = ''
if (not os.path.isfile(cache_file)):
response = urlopen(url)
data = response.read()
html = data.decode('utf-8')
print ("Saved to chache file: ", cache_file)
f1 = codecs.open(cache_file, 'w', 'utf-8')
f1.write(html)
f1.close()
else:
print("Data was taken from cache: ", cache_file)
f = codecs.open(cache_file,'r', 'utf-8')
html = f.read()
return html


 The best way to find amazon product price tag is to use google chrome Inspect Element Tool under Amazon price, find how to do it on the next image:
The best way to find amazon product price tag is to use google chrome Inspect Element Tool under Amazon price, find how to do it on the next image: