How to scrape data from website in C#
If you do not want to read and just want to download c# code samples
Before going to start web scarping in C#, we must have to know. What is Web Scraping? Web Scraping is data scraping that is used for extracting data from websites. The other terms used for web scarping are web harvesting or web data extraction.
Web scraping is used for contact scraping, and as a component of applications used for web indexing, web mining and data mining, online price change monitoring and price comparison, product review scraping (to watch the competition), weather data monitoring, website change detection, research, tracking online presence and reputation, web mashup and, web data integration - you can read more about this on our page about web scraping service.
Web Scraping with C#
With the passage of time, the process of extracting data is increasing. The data in different websites can be accessed through their web API or web services. If some websites don't provide or allow access to their data then Web scraping is used which is used to accessed data. Web scraping allowing developers to simulate and automate to human browsing behavior to extract content files, images, and other information from web applications to perform specific task. Now I'm going to show you how scrap a website with C# here on Mydataprovider. I'm going to scrap eBay which is very famous website using C#. This process follows a procedure and the procedure contains different steps which are as follow in details.Video Demo

Lets develop Web Scraper with c# for Ebay
Open Visual Studio. Add new project and choose the C# console application from the template. Name the project as EbayScrapper as shown in fig.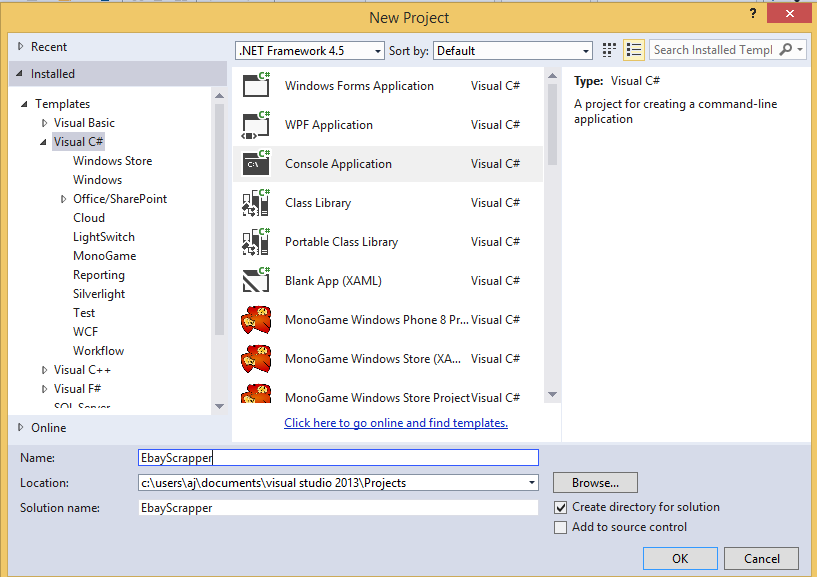 After this go to the website of ebay. Here is the link. https://www.ebay.com
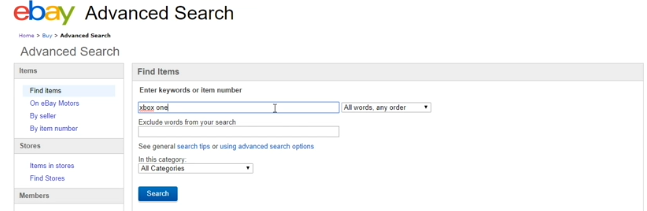
On ebay website go to advanced search and search xbox one. The items related to this will be shown.
After this go to the website of ebay. Here is the link. https://www.ebay.com
On ebay website go to advanced search and search xbox one. The items related to this will be shown.
 Copy this URL and paste it in main program because will scrap this web page later in this article.
Copy this URL and paste it in main program because will scrap this web page later in this article.
Required References
After this we will need to install following from C# NuGet packages by just right click on reference in program directory. 1) HTTPClient 2) HtmlAgilityPack Following are the necessary things for scrapping this website.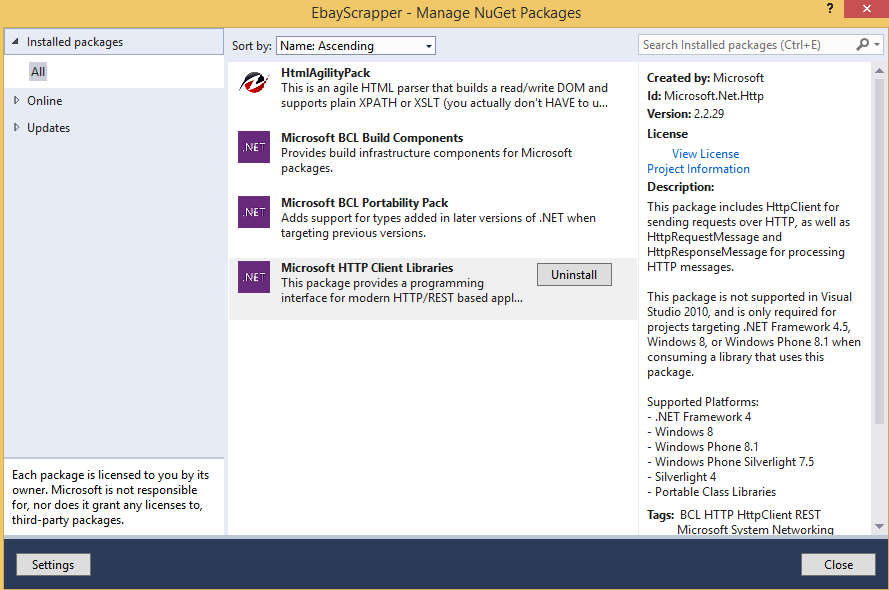 The following code will determine the exactly website code which we can check onto the website.
The following code will determine the exactly website code which we can check onto the website.
static void Main(string[] args)
{
GetHtmlAsync();
Console.ReadLine()
}
Static void GetHtmlAsync()
{
var url ="https://www.ebay.com/sch/i.html?_nkw=xbox+one&_in_kw=1&_ex_kw=&_sacat=0&LH_Complete=1&_udlo=&_udhi=&_samilow=&_samihi=&_sadis=15&_stpos=&_sargn=-1%26saslc%3D1&_salic=1&_sop=12&_dmd=1&";
var httpclient = new HttpClient();
var html = httpclient.GetStringAsync(url);
Console.WriteLine(Result.html);
}
 We just copy and paste website code into notepad to make sure some things which we use later
We just copy and paste website code into notepad to make sure some things which we use later
 Now after this we will parse data from ebay to our application. For this we use Html document. We will write a code for grab list items. We write this code according to the website code.
Now after this we will parse data from ebay to our application. For this we use Html document. We will write a code for grab list items. We write this code according to the website code.
var ProductsHtml = htmlDocument.DocumentNode.Descendants("ul")
.Where(node => node.GetAttributeValue("id", "")
.Equals("ListViewInner")).ToList();
var ProductListItems = ProductsHtml.Descendants("li")
.Where(node => node.GetAttributeValue("id", "")
.Contains("item")).ToList();
Console.WriteLine(ProductListItems.Count());
Console.WriteLine();
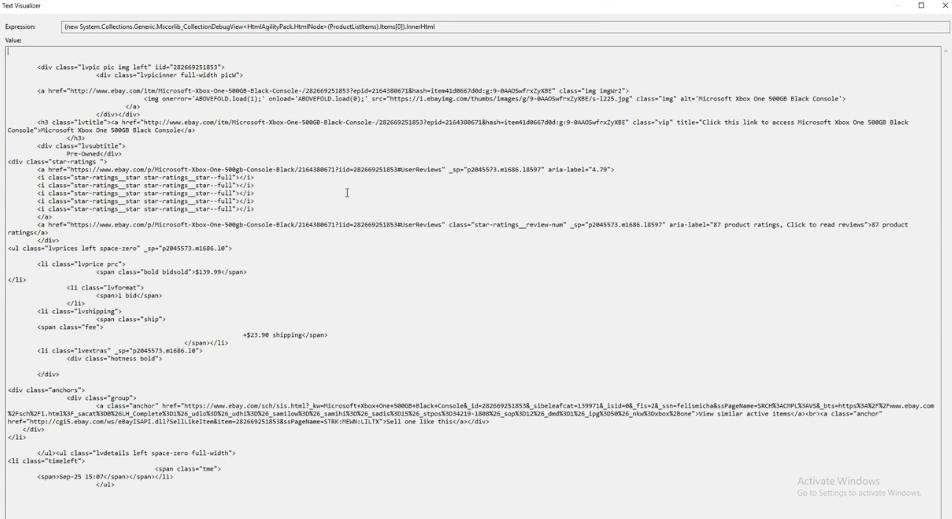 Now this steps will pull out all information from website to my console application. For this I'm going to make some implementation to existing code.
First of all I'm going to use for each loop that will sort things in my console according to website.
First of all I'm going to pull out listing id because every ad on website has unique id. For this I must have to use some additional things in the code which are as follow:
Now this steps will pull out all information from website to my console application. For this I'm going to make some implementation to existing code.
First of all I'm going to use for each loop that will sort things in my console according to website.
First of all I'm going to pull out listing id because every ad on website has unique id. For this I must have to use some additional things in the code which are as follow:
foreach( var ProductListItem in ProductListItems)
{
//ID
Console.WriteLine(ProductListItem.GetAttributeValue("listingid", ""));
//ProductName
Console.WriteLine(ProductListItem.Descendants("h3")
.Where(node => node.GetAttributeValue("class", "")
.Equals("lvtitle")).FirstOrDefault().InnerText.Trim('\r', '\n', '\t'));
 The next thing I'm going to pull out is the price of the product. The price of the product code will also write according to the attribute use in the website code. The code will be shown as follow:
The next thing I'm going to pull out is the price of the product. The price of the product code will also write according to the attribute use in the website code. The code will be shown as follow:
//Price
Console.WriteLine(ProductListItem.Descendants("li")
.Where(node => node.GetAttributeValue("class", "")
.Equals("lvprice prc")).FirstOrDefault().InnerText.Trim('\r','\n','\t')
);
//ListingType
Console.WriteLine(ProductListItem.Descendants("li")
.Where(node => node.GetAttributeValue("class", "")
.Equals("lvformat")).FirstOrDefault().InnerText.Trim('\r', '\n', '\t')
);
//URL
Console.WriteLine( ProductListItem.Descendants("a").FirstOrDefault().GetAttributeValue("href", "")
);
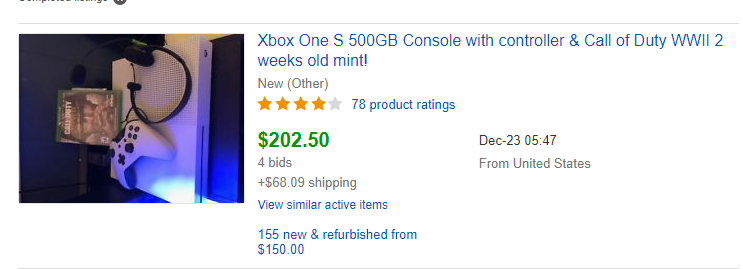
Output
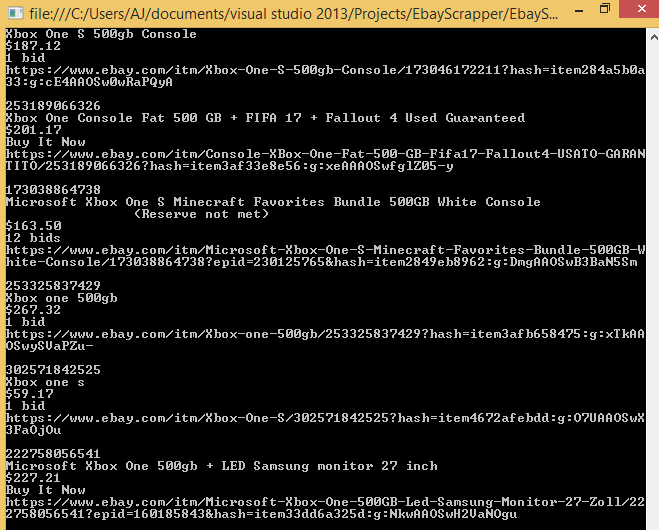
Sample Product
Sample Product on ebey website.