Every day our web scraping service
scrapes millions of web pages into database.
We help our clients to get real-time data from TOP US,Europe,UK,China site.
We can extract data from any site ( it can be online ecommerce stores, marketplaces, job boards ) in any format, including CSV, Excel, TXT, HTML, and databases.
Our universal web scraping solution (we call it “RUNNER”) allows us to export 24/7 any data from the web site. We have own proxies pool (more than 200K proxies for web scraping) that allows us to be not blocked by sites that we scrape.
What is Web Scraping
How often do you need some information from different web sources to be extracted and stored while keeping it easy to use and share? The answer is obvious. We are always in need of some specific data. The most efficient way to obtain the information you need is to use web scraping services. Web scraping, also referred to as data scraping, is the process that includes the extraction of specific data from various websites and their storage in the local databases or spreadsheets.
However, it may be a challenge to arrange the data collection process in a timely manner. In addition, major web scraping tools lack proper functionality when it comes to the extraction of a high volume of data. Scattered data and dynamic websites may cause difficulty for users as well. In this case, it pays to rely on a trusted provider of data scraping services.
MyDataProvider is a dedicated team of professionals able to offer customized solutions that would better suit your particular business needs.
Services and Tools
One time web scraping
Save data to file or your database from source site
Periodical web scraping
Scrape data daily,weekly,hourly or by request and update your database from source site
Web scraping project support
If source site changes design and scraper stops scrape correctly we support you ASAP
Online web scraping tool
Web scraping tool for managing web scraping tasks via web
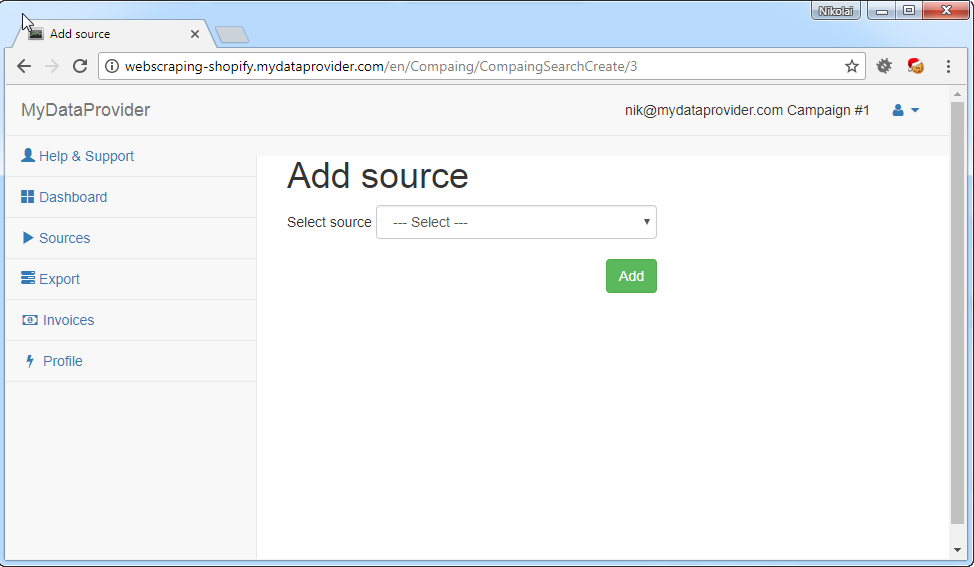
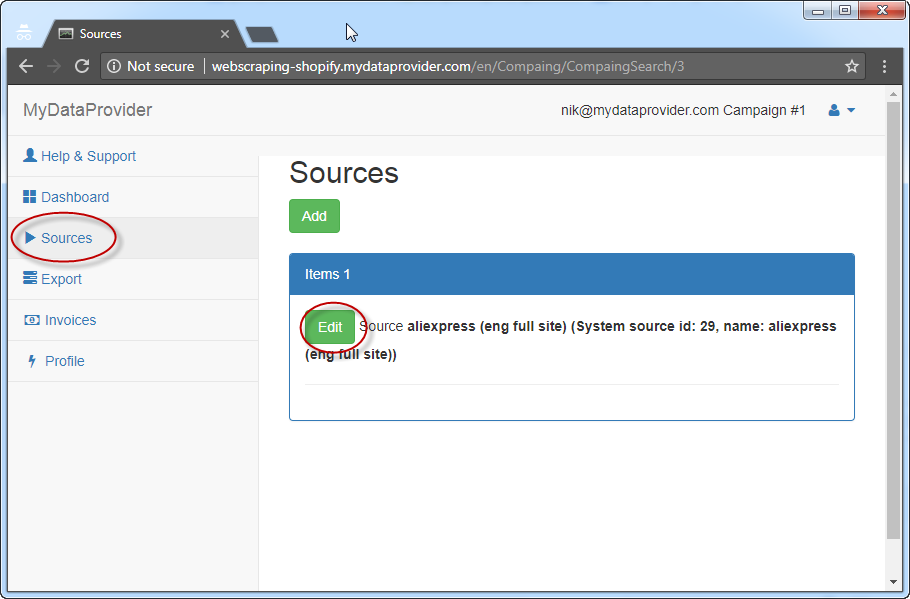
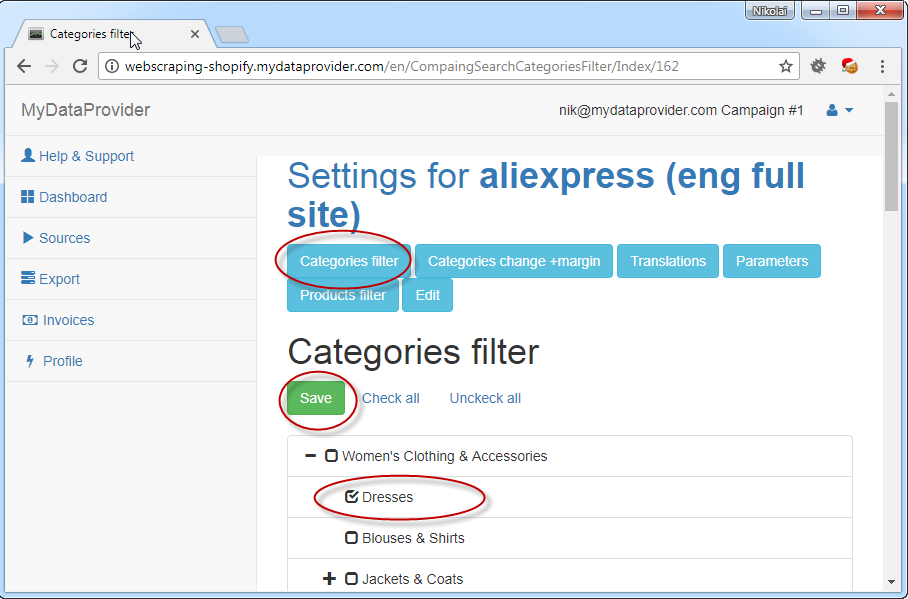
Features
With our proprietary web scraping tool, we provide customized data that enables our clients to achieve their business goals quicker and easier. To manage the tool, our clients don’t need any specific knowledge. The processes of data scraping are flawless and easy to adjust.
Scraping for any website
Be confident that your committed MyDataProvider Team is doing its best to meet your particular business needs
Obtain daily or weekly updated data from web scraping service
Access data through API calls from web scraping service configured for your sites
Export to CSV, JSON, XML or directly to your database
Manage the process of data extraction via online panel for web scraping service
Get information of exceptional quality thanks to the automatic quality checker
Get access to the scraper data via web browser
Find here the most important features.
WebScrapers Runner is an online service for data extraction from the Internet. In 2009, MyDataProvider created the service based on the company’s proprietary web scraping tool. Today, we are ready to provide any type of data extraction configuration and customize it to flawlessly meet the needs of our clients. For our customers, managing data extraction via web browser is easy and does not require any special skills.

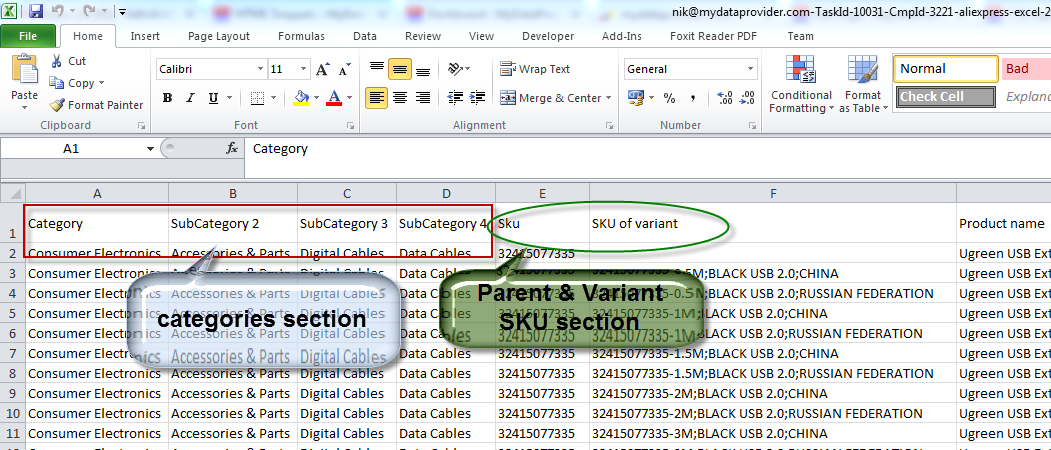
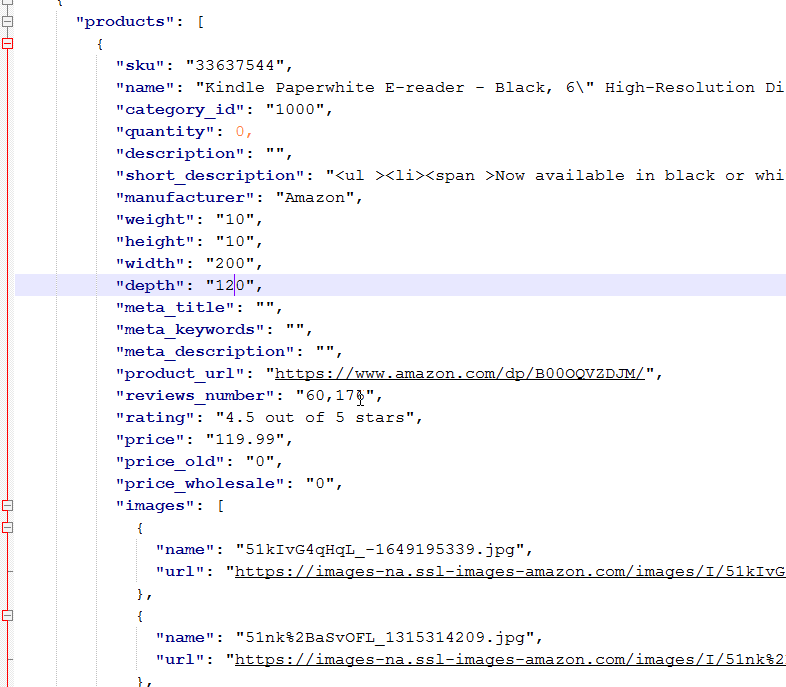
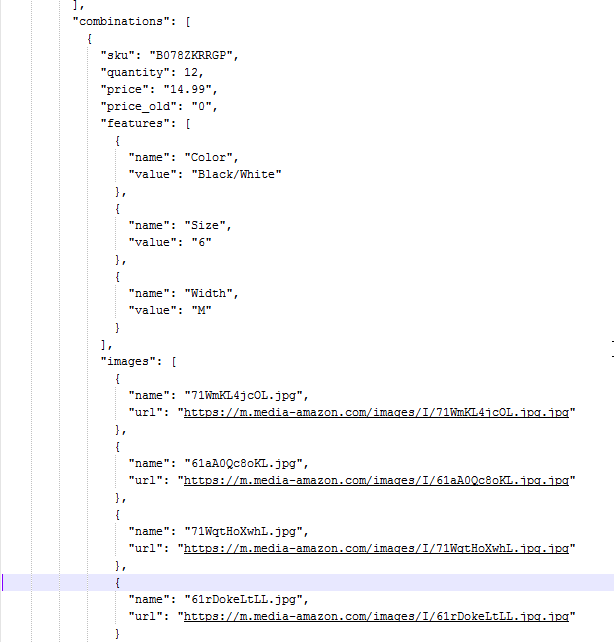
Bulk extraction. Extract data from all categories or just a specific category / product URLs.

The data are well-structured and easy to process.

Take any fields, images, options, variants, features for items.

Export data to different formats and databases.
– CSV, JSON, XML, MS Excel.
– MySQL, PostgreSQL, MS SQL.
– import into online stores.

Scheduler allows for the data extraction at stated intervals.

Your personal manager is happy to assist if you have any questions.

Get the extracted reports to your email.

Search items by keywords, SKU, brand, ID, and URL.
We Offer Web Scraping Services
Since 2009, MyDataProvider has offered services in web scrapping and price monitoring. With the company’s ten-year expertise in monitoring and web scraping, MyDataProvider delivers customized solutions that meet and exceed expectations of our customers. MyDataProvider’s highly professional team allows its customers to focus on their core competencies while avoiding any risks, and saving time and money.
MyDataProvider considers it as its mission to assist e-commerce companies in managing their information. Delivering valuable data in efficient and timely manner, MyDataProvider contributes to their increased agility, enhanced flexibility, and improved insights.

Get Any Data
We harvest data from any website and deliver them in your preferable format.

Get High Quality Data
Our automatic quality checker ensures data accuracy.

Get Data Quickly
It takes only 4-8 working days to develop a new scraper.
FAQ
Frequently asked questions.
What data export formats are available?
Our clients receive the data in the most popular formats, including MS Excel, CSV, JSON, and XML. We can also share the data via an API and export them directly to your online store, if needed.
Can you scrape non-English websites?
Yes, we can. We have a profound experience in scraping websites in languages other than English, including Estonian, Polish, Russian, Spanish, and Taiwanese Hokkien.
Is it possible to scrape data behind a login page?
Yes, it is possible. Having an active account on the required website allows for the data scraping behind the login page. After the login, the crawling is no different than crawling in a standard way. However, it is well to bear in mind that some data might be available only to the registered users and additional terms of use may apply.
Do you collect data from various locations?
Yes, we do. Possessing a technique to collect the data from multiple locations, we make multi- regionality our competitive advantage.
Is it possible to scrape the delivery of products from one country to another?
Yes, we can scrape data of product delivery into the service we provide.
For some web scraping service providers, it may seem challenging to extract product pages properly. How about that at MyDataProvider?
With our 10-year expertise, we are able to do it properly. We at MyDataProvider have developed a special procedure so our customers could receive the accurate data.
Are you focused on custom web scraping or deliver standardized solutions?
Our primary task is to make data extracted fully customized. Indeed, we have some scrapers are assigned only for tests and demo. However, our practice shows that each client requires unique scraper as each business has its own needs.
What support do you offer?
The support depends on the plan. If it is one-time extraction, we extract the data that clients want to receive and in the format and volume they need.
Do you provide your clients with data samples before purchasing?
We provide samples of a particular number of sites if we have data samples. If there are no samples, we just show export file format generated by our software. Additionally, before running any project we create a technical specification to be sure that we understand all project requirements and our clients know what they receive at the end of the development process.
Can your platform perform multi-lingual scraping too?
Yes, it can. There are two options of the extraction. The first one allows you to scrape data in different languages. The second one is used when it will be done in one data set.
Do you crawl sites that require login?
Yes, we do it but it requires some special preparations from the client side and it certainly increases project development time.
Do you provide a one-time data extraction?
Sometimes we have clients who need just to receive the contacts or the data for brief analyses. As we always do our best to meet the requirements of our customers, we provide such type of service certainly.
Сustom Web Scraping Service
Does your business depend on real-time data in a quickly changing environment?
Do you have special requirements when automating your data extraction and delivery? Do the standard web-scrapers not reach your specific business goals?

Where Is Customized Web Scraping Used?
Custom web scraping service is the most cost-efficient way to extract data from millions of websites providing high-quality data that is compatible with your specific business needs.
Customized web scrapping is widely used for:
• Real estate listings gathering: real estate agents and MLS companies;
• Email address collecting: a great number of companies use it for lead generation in marketing;
• Product review scrapping: this is how many wholesalers and trading companies keep an eye on their competitors and do the price check;
• Developing new sites: as a rule, they collect similar data from various web resources and then combine it;
• Data retrieval from social media websites: it is widely used by social media companies;
• Scraping to obtain an immense amount of data: it’s frequently used for further analysis by the research companies;
• One-time scrapping: every company needs to collect a great deal of data for a very specific purpose.
Why MyDataProvider?
Because you will get all the things completed.
Since 2009, Mydataprovider has provided custom software development services. With a focus on web scraping, price monitoring, and repricing services, we deliver solutions that meet or exceed the expectations of our customers.
The reputation of our company is strengthened by loyalty and trust of numerous satisfied customers and throughout various industries.
Cost savings
Mydataprovider supports more than 100 TOP websites + our pricing is startups friendly.
1000x more data
Using our tools you could extract tons of data.
Get faster
2 times faster to market. Average time for 1 new scraper development take 2-3 days!
Our Customers

How can you use Web Scraping?
| Method | Recommendations |
Products Content extraction |
Get a solution to extract the content of any website. For each product, it is possible to extract the following: – name, sku, price, description, – all images, – features, – options (size, color, etc), – categories with structure. |
Price Monitoring & Price History |
Receive real-time reports with current prices & stocks.
|
API |
Access the extracted data via API calls. Receive the data in a structured CSV, XML or JSON file. |
Dropshipping |
Use Web Scraper for dropshipping and export the data from a website into your store. We will generate a file with the data (csv, xml, json or excel) and you will import the data directly into your online store, including shopify, woocommerce, opencart, prestashop, and ccvshop. |
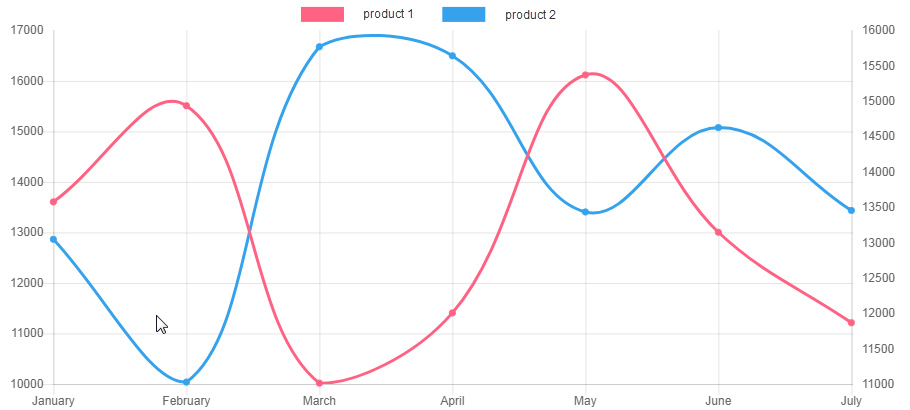
Price Drops |
Analyze prices changes. Get real-time reports on price drops by email.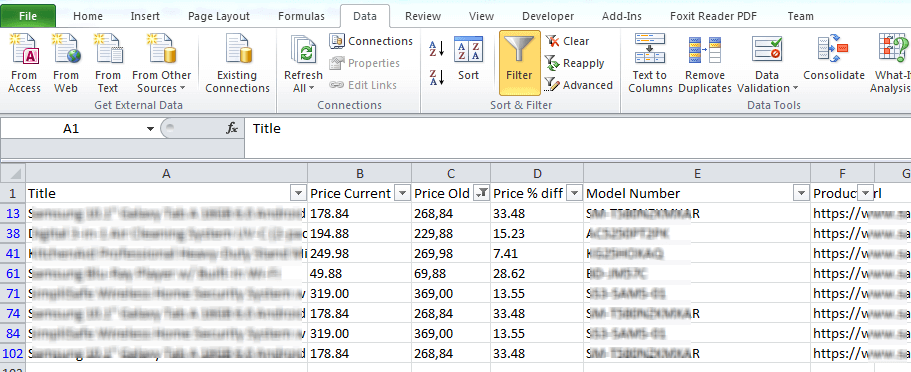
|
Popular Web Scrapers
Amazon Web Scraper
Lowes Web Scraper
Costco Web Scraper
Homedepot Web Scraper
Banggood Web Scraper
Lazada Web Scraper
Aliexpress Web Scraper
Walmart Web Scraper
Newegg Web Scraper
Web have experience at ECOMMERCE WEB SCRAPING!
What eCommerce data you can scrape
– products details, variants.
– features, options.
– images, descriptions.
– reviews.
– prices, availability.
How you can get results
– files: csv, excel, xml, json.
– online dashboard where yo can run web scraper.
– direct import to your online store with daily sync.
– import to shopify, woocommerce, prestashop.
– web api.